
Lernen mit KI – #Technologie
Section outline

-
-
Exkurs II: Maschinelles Lernen und künstliche neuronale Netze
Dem Vorbild biologischer Neuronen

Quelle: https://commons.wikimedia.org/wiki/File:Neuron_-_annotated.svg) bzw. https://gamedevacademy.org/perceptrons-the-first-neural-networks/
sind künstliche Neuronen nachempfunden. Im einfachsten Fall sind verschiedene Neuronen miteinander verbunden und befolgen abhängig von Informationen, die bei einen eintreffen, bestimmte Anweisungen, um als Ganzes - nicht das einzelne Neuron - eine bestimmte Aufgabe zu lösen.
Motivierendes Beispiel: Brain in a bag:
Das gut nachvollziehbare Snap-Spiel findet sich hier: https://teachinglondoncomputing.org/resources/inspiring-unplugged-classroom-activities/the-brain-in-a-bag-activity/ und funktioniert folgendermaßen:
Das aus sieben Neuronen aufgebaute Netz hat vier sehende Neuronen auf der linken Seite,
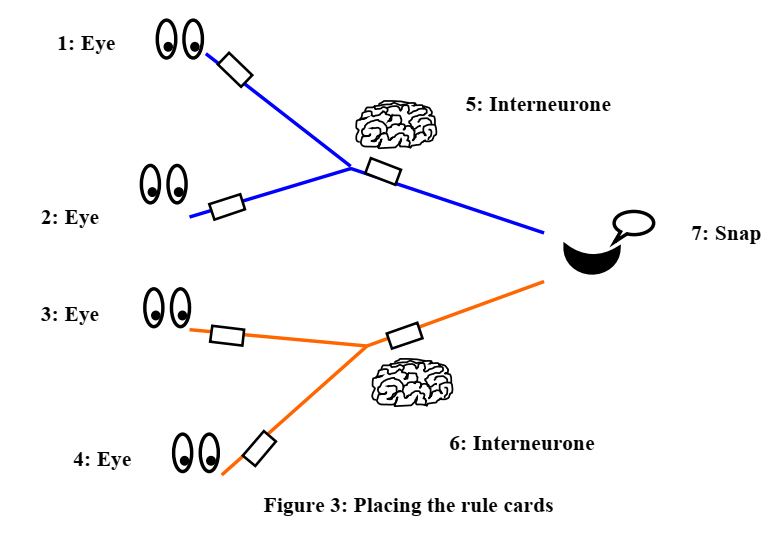
sie reagieren von oben nach unten folgendermaßen:
N1 feuert bei einer roten Karte in Position #1
N2 bei einer roten Karte in Position #2
N3 bei einer schwarzen Karte in Position #1 und
N4 bei einer schwarzen Karte in Position #2
Je nachdem, welche Karte sie "sehen", leiten sie ihre Kugel an die mittlere Schicht weiter ("feuern"). In dieser befinden sich zwei weitere Neuronen N5 und N6.
Diese folgen der Anweisung, ihre Kugel nur dann an das 7. Neuron N7 weiterzuleiten (zu feuern), wenn sie selbst zwei Kugeln erhalten haben.
Das 7. Neuron soll schließlich "Snap" rufen (feuern), falls es eine Kugel weitergeleitet bekommen hat.
Für einen Durchlauf werden nun den sehenden Neuronen N1 bis N4 zwei Karten gezeigt.
Sind beide rot, feuern zunächst N1 und N2, N5 erhält also zwei Kugeln und feuert ebenfalls, was schließlich auch N7 feuern, also "Snap" rufen lässt.
Analog ertönt auch "Snap", wenn beide Karten schwarz sind (N3 und N4 feuern, dann N6 und schließlich wieder N7). Sind die Karten hingegen verschiedenfarbig, bleibt es still.
Das neuronale Netz kann also entscheiden, ob die beiden gezeigten Karten gleich- oder verschiedenfarbig sind, ohne einen Begriff von Gleichheit oder Verschiedenheit zu besitzen oder irgendetwas gelernt zu haben.
In gewisser Weise ist es also einem Computerprogramm oder einem Algorithmus vergleichbar.
Als kleine Übung kann man sich überlegen, wie man das Netzwerk anpassen müsste, damit nicht rot von schwarz, sondern Position #1 von Position #2 unterschieden werden kann.
Mit "lebenden" Neuronen wird das Ganze unter dem Titel "Brain in a bag" vorgeführt:
Vorlagen zum Ausdrucken der Karten gibt es hier: https://cs4fndownloads.files.wordpress.com/2016/06/buildabrainquickguidev1.pdf
Eine Variante auf Deutsch mit zehn statt sieben Neuronen ist hier dargestellt: https://unterrichtsmaterial-ddi.cs.upb.de/Brain_in_a_bag
Eine Brettspiel-Variante mit Münzen, das auf "beide Kopf" oder "beide Zahl" entscheiden kann, gibt es hier: https://cs4fndownloads.wordpress.com/build-a-brain-coin-snap/
Ein allgemeines künstliches neuronales Netz, kurz KNN, wird gegenüber obigem Beispiel noch um eine wesentliche Komponente erweitert, nämlich die sogenannten Gewichte: Jeder Verbindung zwischen zwei Neuronen wird eine Zahl zugeordnet, die auch negativ sein kann, und bestimmt, welchen Einfluss dieses Neuron auf das Feuern des nächsten hat.
Gewichte sind zentral für das im Folgenden zu betrachtende Training, da sie die Parameter und damit Stellschrauben darstellen, damit das neuronale Netz letztendlich die von ihm geforderte Aufgabe erfüllt. Auch in der Natur findet man dieses Konzept wieder.
Zusammenfassend besteht also ein künstliches neuronales Netz aus folgenden Komponenten:
-
dem Input, das entspricht in obigem Beispiel den gezeigten Karten
-
dem Output, das ist "Snap" oder Stille im Snap-Spiel
-
den Gewichten, also dem Einfluss der einzelnen Neuronen auf ihre Nachfolger; im Beispiel ist das stets eins
-
der Summierungsfunktion, die bestimmt, wie für ein einzelnes Neuron die gewichteten Ergebnisse der Vorgängerneuronen zusammengezählt werden; oben wurde einfach "+" gerechnet, das kann aber auch komplizierter werden
-
der Aktivierungsfunktion, die angibt, wenn das Neuron feuert; diese war oben für (fast) alle Neuronen unterschiedlich: N1 bis N4 feuerten abhängig von dem Gesehenen, N5 und N6 bei genau zwei Kugeln und N7 bei genau einer Kugel
Visualisiert wird dieser Aufbau für ein einzelnes Neuron häufig in folgender Form (w sind die Gewichte, das griechische Sigma steht für die Summierung und das Integralzeichen für die Aktivierung):
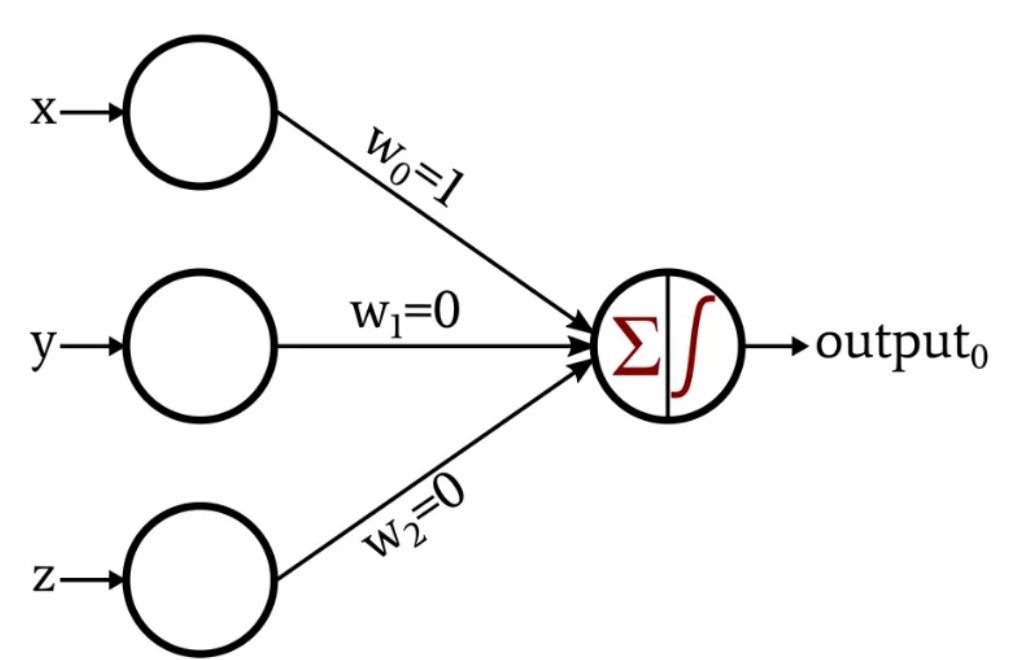
Quelle: https://www.allaboutcircuits.com/technical-articles/how-to-train-a-basic-perceptron-neural-network/
Eine weitere Zutat, das sogenannte Bias, eine Art Verschiebung, wird hier der Einfachheit halber nicht weiter berücksichtigt.
Ein Netz besteht natürlich üblicherweise aus nicht nur einem, sondern mehreren Neuronen und sieht typischerweise so aus:
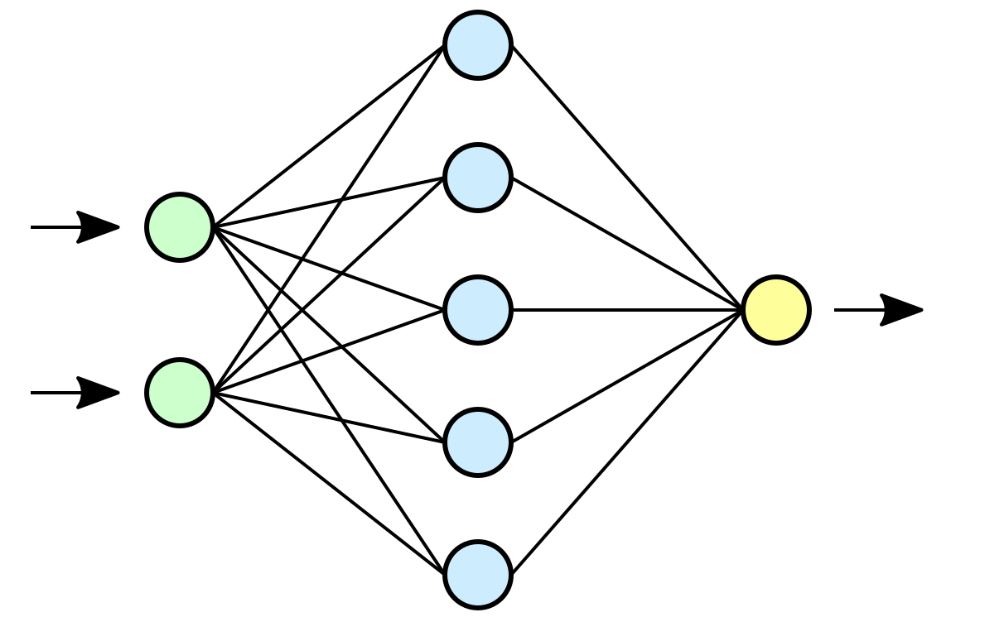
Quelle: Wikipedia, https://de.wikipedia.org/wiki/K%C3%BCnstliches_neuronales_Netz
Ergänzend zum obigen Beispiel sollen hier zwei weitere einfache KNNs betrachtet werden, die nur aus einem Neuron und zwei Eingängen bestehen. Ein so einfaches Netz wird auch als Perzeptron bezeichnet:
a) Logisches Oder:
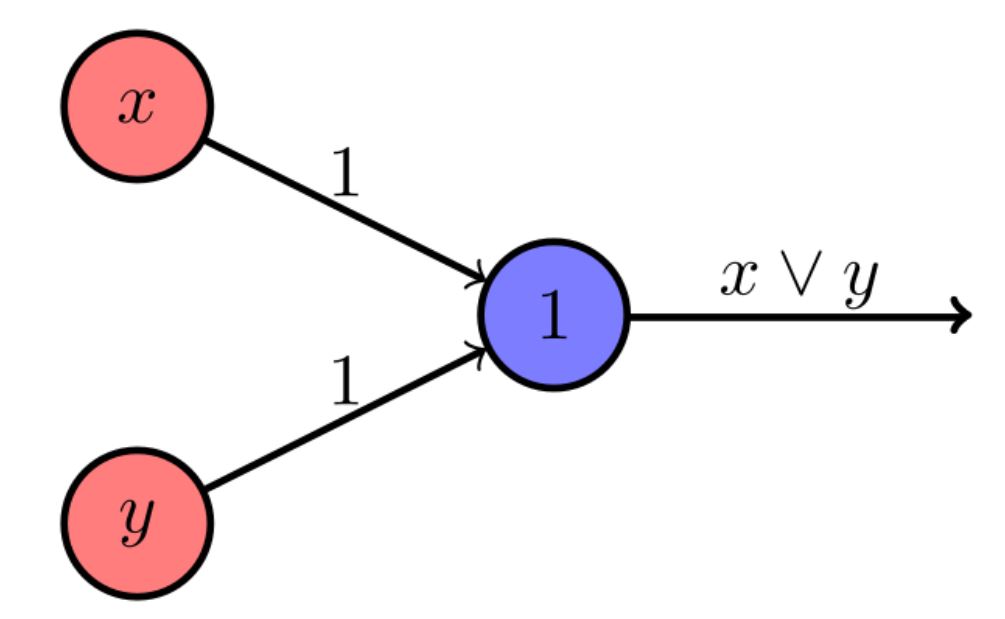
Quelle: https://de.m.wikipedia.org/wiki/Datei:Perceptron-or-task.svg
Die Gewichte an den Verbindungslinien zwischen den Eingängen und dem blauen Neuron sind hier wiederum alle 1, die Summationsfunktion die einfache Summe und die Aktivierungsfunktion auch 1 - das ist die 1 in dem blauen Kreis -, was bedeutet, dass das blau gefärbte Neuron dann feuert, wenn es mindestens den Wert 1 erhält.
Als Eingabewerte für x und y nutzen wir jetzt der Einfachheit halber 0 und 1, könnten aber genau so gut wieder mit Kopf und Zahl arbeiten.
Sind x und y beide 0 so kommt beim blauen Neuron auch eine 0 an (0 mit Gewicht 1 bleibt beide Male 0), ist hingegen entweder x oder y gleich 1, so erhält das blaue Neuron mindestens den Wert 1, feuert also.
Das neuronale Netz "kann" also entscheiden, ob beide Eingänge 0 waren, oder mindestens einer von Null verschieden.
Betrachtet man das Netz etwas genauer, so kann es sogar deutlich mehr: Es feuert z.B. auch bei x = 0.5 und y = 0.5 oder bei x = 0.2 und y = 0.9, immer dann also, wenn x und y zusammen mindestens 1 ergeben. Das lässt sich folgendermaßen visualisieren:
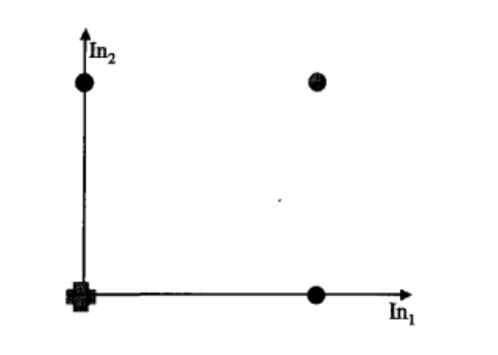
Alle Punkte, die oberhalb der Verbindungslinie von Punkt (1,0) und (0,1) liegen, werden durch dieses Netz voneinander getrennt.
Abwandlung 1:
Man sieht schnell ein, dass man das neuronale Netz leicht hätte modifizieren können, um das gleiche Ergebnis zu erzielen: Statt der Summationsfunktion 1 hätte man auch 0.5 oder 0.9 oder auch 0.1 wählen können.
Nur größer als 1 hätte zu einem falschen Ergebnis geführt, da dann das Neuron bei x=0 und y=1 bzw. x=1 und y=0 nicht mehr gefeuert hätte.
Abwandlung 2:
Auch die Gewichte hätte man ändern können. So sind größere, gar verschiedene Zahlen möglich, aber auch kleinere, so lange sie größer als Null bleiben, dann muss man allerdings u.U. die Aktivierungsfunktion auch anpassen.
Festzuhalten gilt, dass es nicht DAS neuronale Netz zur Lösung einer Aufgabe gibt.
b) Logisches Und:
Ersetzt man in dem obigen Netzwerk die Summierungsfunktion durch eine 2, so feuert das Netzwerk nicht mehr bei x=0 und y=1 oder x=1 und y=0, sondern nur noch bei x=1 und y=1.
Das so abgeänderte Netzwerk kann also jetzt entscheiden, ob beide Eingänge 1 waren oder nicht.
c) Experimente:
Gehen Sie bitte auf die Seite https://phiresky.github.io/neural-network-demo/ und ändern Sie rechts unter Net 3 layers auf 2 layers ab.
i) Mit dem Knopf "Remove" rechts oberhalb des Koordinatensystems entfernen Sie zunächst alle roten und grünen Punkte.
Setzen Sie dann gezielt einen roten Punkt auf den Koordinatenursprung (0,0) und drei grüne Punkte auf die Punkte (1,0), (0,1) und (1,1).
Drücken Sie nun den Knopf "Animate" links unter dem neuronalen Netz und schauen Sie zu, wie die Gewichte nach und nach erhöht werden, und betrachten sie auch die roten und grünen Bereiche.
Fügen Sie schließlich weitere rote und grüne Punkte hinzu und beobachten, was geschieht. Achten Sie insbesondere darauf, wie viele Punkte richtig klassifiziert werden.
Stoppen Sie die Animation und drücken auf "Reset".
ii) Entfernen Sie wie unter 1 wieder alle Punkte und setzen Sie dann gezielt drei rote Punkte auf den Koordinatenursprung (0,0) und auf die Punkte (1,0) und (0,1) und einen grünen Punkt auf (1,1).
Wiederholen Sie die Experimente aus i).
Stoppen sie zum Schluss die Animation und drücken auf "Reset".
iii) Wahrscheinlich haben Sie jetzt schon ein Gefühl dafür bekommen, welche Punktkonstellationen das System trennen kann und welche nicht mehr möglich sind.
Als Beispiel diene Folgendes: zwei rote Punkte auf (0,1) und (1,0) und zwei grüne Punkte auf (0,0) und (1,1).
Hier werden immer nur zwei Punkte richtig sein.
Schließlich fügen Sie unten (s. i)) wieder einen Layer hinzu und versuchen es erneut.
Warten Sie nach dem Betätigen der "Animate"-Taste ein wenig und schauen Sie sich an, was Wundervolles geschieht. Statt einer Trennungslinie sollte hier jetzt ein Streifen erkennbar sein. Dann fügen Sie auch hier weitere Punkte hinzu und beobachten. Insbesondere sollten Sie auch negative Gewichte sehen, erkennbar an roten statt der sonst blauen Pfeile.
BONUS: unter dem blauen Auswahlmenü "Load Preset" können Sie mit vorgegebenen Netzkonstellationen weitere Experimente durchführen.
Als Quintessenz aus diesen Experimenten ergibt sich, dass nicht jedes Problem mit einem einfachen Perzeptron gelöst werden kann. Für komplexere Aufgaben sind möglicherweise noch mehr Layer nötig.
Einfache neuronale Netze lassen sich noch durch Nachdenken entwerfen, wie oben die beiden für die Und- und Oder-Verknüpfung; bei komplexeren Aufgaben, so z.B. schon das Trennen der beiden Punkte (0,1) und (1,0) von den Punkten (0,0) und (1,1) wird das aber immer schwieriger bis unmöglich.
Vorgegeben ist meist, welche Eingaben gemacht werden sollen, und was das Ergebnis sein soll.
Wie viele Zwischenlayer mit jeweils wie vielen Neuronen gebraucht werden, ist zu Beginn allerdings alles andere als klar und auch wie die Gewichte richtig gewählt werden.
Das Ziel soll immer sein, dass das Netz eine möglichst hohe Trefferquote bekommt.
Lernprozess
Daher wählt man nach Festlegung der Anzahl der Zwischenschichten und der Anzahl Neuronen pro Zwischenschicht zunächst zufällige Werte für die Gewichte, lässt das neuronale Netz seine Arbeit tun und schaut, wo Fehler aufgetreten sind. Durch ein Verfahren, das unter der Bezeichnung Back-Propagation firmiert, werden dann abhängig von den gemessenen Abweichungen Korrekturen für die Gewichte von hinten nach vorne vorgenommen, das Netz erneut durchlaufen, wieder die Fehler gemessen und so fort.
Zur Illustration des Lernprozesses diene das Spiel "Train a neuron":
http://www.cs4fn.org/machinelearning/trainaneuron.php
Download-Link: https://cs4fndownloads.files.wordpress.com/2016/06/train-a-neuronguide.pdf
Zusammenfassend lässt sich der Gesamtprozess so beschreiben:
Aus einem Vorrat von Daten, auf die hin das KNN trainiert werden soll, werden etwa 80 % als Trainingsdaten und 20 % als Testdaten verwendet.
-
Trainingsphase: Nach Festlegung der Netzstruktur und zufällige Wahl der Gewichte wird das System mit den Trainingsdaten trainiert, bis es die gewünschte Zuverlässigkeit erreicht hat.
-
Testphase: Im Anschluss wird mit den Testdaten überprüft, ob wirklich die im Training erhaltene Erfolgsquote erreicht wird.
-
Anwendungsphase: Ist das Netz nun ausreichend trainiert, kann es z.B. auf dem Handy zur Bilderkennung genutzt werden. Es lernt nicht mehr weiter, macht also immer dieselben Fehler.
In einer Simulation lässt sich verfolgen, wie für unser Beispiel iii) von oben nach und nach die Gewichte angepasst werden.
ChatGPT
-
175 Mio. Parameter = Gewichte
-
Trainingsdaten:
Lerntypen
Ein neuronales Netz kann auf dreierlei Arten lernen.
Quelle: https://souravisinha.medium.com/chapter-3-machine-learning-types-and-their-applications-7b9f3fb8fc21
-
Supervised Learning = überwachtes Lernen: Hierbei werden die Outputs komplett vorgegeben oder anders ausgedrückt: die Trainingsdaten sind gelabelt. Das ist allerdings sehr aufwändig und begrenzt die für das Training verfügbaren Datensätze.
-
Unsupervised Learning = unüberwachtes Lernen: Ergebnisse werden nicht vorgegeben, das System soll selbstständig Muster erkennen.
- Reinforcement Learning = verstärkendes Lernen: Es werden weder Ergebnisse vorgegeben noch wird das System sich selbst überlassen. Vielmehr wird ihm nach jedem Durchgang zurückgemeldet, ob sein Ergebnis gut war oder nicht. Begrifflich stehen hier Belohnung für positive Verstärkung und Bestrafung für negative.
Ein wunderschönes Beispiel für verstärkendes Lernen ist das Spiel "Schlag den Roboter", bei dem man der KI regelrecht zuschauen kann, wie sie lernt zu spielen ohne irgendetwas über das Spiel zu wissen: https://www.stefanseegerer.de/schlag-das-krokodil/?robots=true, in der Anlag-Version: http://www.aiunplugged.org/, Spielbrett: https://computingeducation.de/3caf5f6b369c1df9377c7d2eb270e8d1/ai-3-spielbrett.pdf, zum Hintergrund: https://computingeducation.de/proj-schlag-das-kroko/
Wie das Spiel zeigt, ist hier gar nicht mal immer eine umfangreiche Datenbasis vonnöten.
Das NIM-Spiel als alternatives Beispiel: https://www.i-am.ai/de/build-your-own-ai.htmlund schließlich noch das Streichholz-Schach https://tu-dresden.de/ing/informatik/smt/ddi/ressourcen/dateien/eduinf/workshop-ki/Streichholz-Schach.zip
Zu AlphaGo z.B. heißt es: "These neural networks were trained by supervised learning from human expert moves, and by reinforcement learning from self-play."
Es hat also zum einen von Experten gelernt, aber dann auch schlicht gegen sich selbst gespielt.
ChatGPT
-
unüberwachtes Lernen
-
verstärkendes Lernen beim Nachtrainieren
Quelle: https://www.ingenieur.de/technik/fachbereiche/ittk/chatgpt-ist-ueberall-doch-wo-kommt-es-her/
Eine schöne Übersicht der verschiedenen Lerntypen findet man hier: https://computingeducation.de/proj-ml-uebersicht/
-
-
-
{kind=link}
{kind=link}