Modul 08
| Website: | Open E-Learning-Center Niedersachsen (OpenELEC) |
| Kurs: | Kompetenzen für das Unterrichten in der digitalen Welt |
| Buch: | Modul 08 |
| Gedruckt von: | Gast |
| Datum: | Samstag, 27. Juni 2026, 07:29 |
Inhaltsverzeichnis
- 1. Daten, Informationen und Wissen
- 2. Von Daten zu fachlichem Wissen
- 2.1. Londons Cholera Ausbruch 1854
- 2.2. Datenerfassung und -gewinnung
- 2.3. Datenbereinigung
- 2.4. Modellierung, Implementierung und Optimierung
- 2.5. Verarbeitung und Analyse
- 2.6. Visualisierung
- 2.7. Evaluation
- 2.8. Evaluation II (mögliche Lösung)
- 2.9. Austausch, Archivierung und Löschung
- 2.10. Snows großes Experiment
- 3. Big Data
- 4. Daten im Unterricht
- 5. Selbsttest
- 6. Literaturempfehlungen
- 7. Abschluss Modul 08
1. Daten, Informationen und Wissen
Übersicht über die Kapitel:
1.1 Daten entdecken
1.2 Daten und Visualisierungen
1.3 Daten, Information und Wissen
1.1. Daten entdecken
Nachdem Menschen nicht besonders gut darin sind, Daten in Rohform zu verarbeiten, sind Visualisierungen und interaktive Tools bei der Arbeit mit Daten besonders hilfreich, vereinfachen sie unseren Blick auf Daten doch ungemein.
Unten finden Sie eine interaktive Grafik, die die Lebenserwartung und die Anzahl Kinder je Frau in verschiedenen Ländern im Laufe der Zeit darstellt.
Unten finden Sie eine interaktive Grafik, die die Lebenserwartung und die Anzahl Kinder je Frau in verschiedenen Ländern im Laufe der Zeit darstellt.
Analysieren Sie die interaktive Grafik und entscheiden Sie, welche der folgenden Aussagen Sie aufgrund der Visualisierung treffen können und welche nicht!
Hinweis: Sie können die Animation mit Klick auf die Play-Taste starten und durch Klicken der Pause-Taste stoppen. Verweilen Sie mit der Maus über einem der Kreise, so wird Ihnen das Land angezeigt. Ein Klick auf einen der Kreise zeichnet den Verlauf ein. Nutzen Sie die Suche, um ein Land zu finden (englische Bezeichner verwenden: Cambodia, Zimbabwe oder Niger).
1.2. Daten und Visualisierungen
Korrelation und Kausalität

- Verhalten sich zwei Datensätze "ähnlich", so spricht man von Korrelation.
- Kausalität hingegen beschreibt einen Ursache-Wirkung-Zusammenhang.
Beim Suchen von Zusammenhängen muss man aufpassen: Korrelation ist nicht gleich Kausalität. Wenn beispielsweise viele Suchanfragen zu Grippesymptomen in einer Region auftreten, so heißt dies noch nicht, dass die Grippe dort besonders stark wütet. Immerhin kann es ein drittes Merkmal geben, das die beiden anderen beeinflusst.
Linktipp:
Der Blog Scheinkorrelation sammelt amüsante Beispiele. Dort werden u.a. Habilitationen von Frauen im Bereich der Humanmedizin bzw. den Gesundheitswissenschaften (cyan) der Anzahl an Platin-Awards für Musikprodukte von Helene Fischer (blau) gegenübergestellt.
Vielleicht ist aber auch nur uns der offensichtliche Zusammenhang entgangen *grübel*.

Korrelation: 0,9674; Quelle: scheinkorrelation.jimdo.com/
Datenvisualisierungen
Ziel einer "Datenvisualisierung" ist es, Informationen so aufzubereiten, dass sie für uns leichter zu interpretieren sind.
Dies ist eine wichtige Methode, mit deren Hilfe wir Muster, Trends oder Korrelationen finden können, die wir sonst vielleicht nicht entdeckt hätten.
Bei der Visualisierung von Daten geht es darum, eine Darstellung zu wählen, die es erlaubt, schnell die Kernaussage zu erfassen – ohne den Betrachter in die Irre zu führen. Um den Trend einer Aktie zu visualisieren, ist ein einfaches Liniendiagramm ausreichend. Je mehr Parameter wir allerdings dazunehmen, desto komplexer wird unsere Visualisierung.
Ein schon älteres, aber sehr berühmtes Beispiel, kennen wir aus dem Chemieunterricht: das Periodensystem der Elemente. Es ist ein Beispiel dafür, wie aus Textdaten eine interessante und nützliche Darstellung werden kann, indem Zeilen und Spalten verwendet werden, um verschiedene Elemente zu gruppieren, und Farben, um darzustellen, ob es sich um ein Edelgas, Halbmetall, usw. handelt.

Das Periodensystem der Elemente ist ein klassisches Beispiel für Datenvisualisierungen.
Linktipp: Das Periodensystem für Datenvisualisierungen
Das Periodensystem für Datenvisualisierungen visualisiert eine Vielzahl möglicher Darstellungen.Linktipp: Information is beautiful
Spannende Beispiele gibt es außerdem auf der Website Information is Beautiful.
Wie unterschiedliche Datenvisualisierungen beim Erfassen der Kernaussage helfen können, zeigt das folgende Applet. Probieren Sie es doch einmal aus!
Der Abschnitt Datenvisualisierungen stellt ein Derivat des unter CC-BY-SA stehenden CS Field Guide Kapitels dar.
Manipulation von Visualisierungen
Diagramme lassen sich leicht manipulieren, um Daten anders erscheinen zu lassen, als sie sind. Dazu reicht es oft schon, einen anderen Ausschnitt der Datenwerte oder eine andere Form der Darstellung zu wählen.
Im folgenden Beispiel sind dreimal die selben Daten dargestellt. Lediglich der Ausschnitt der x- und y-Achse wurde verändert. Dennoch kommt man beim oberflächlichen Betrachten des Diagrammes schnell zu sehr unterschiedlichen Schlüssen!
Daher gilt der scherzhafte Merksatz: "Vertraue keinem Diagramm, das du nicht selbst gefälscht hast".
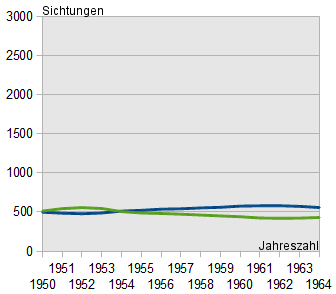
"In den letzten Jahren gab es kaum Veränderungen. Es besteht also kein Anlass zur Sorge."
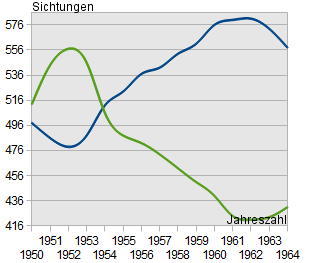
"In den letzten Jahren gab es drastische Veränderungen! Wir müssen dringend etwas unternehmen!"
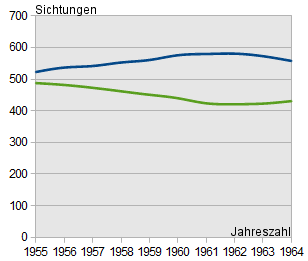
"In den letzten Jahren gab es immer mehr Falken als Mäuse. Das wird auch so bleiben"
Dieser Abschnitt ist von Martin Forster unter CC-BY-SA lizenziert.
1.3. Daten, Information und Wissen
Die Begriffe Daten und Information haben wir bereits häufiger verwendet. Wann aber wird aus diesen Daten Information oder sogar Wissen? Das erfahren Sie im Video.
Es gibt in unterschiedlichen Disziplinen teilweise andere Sichtweisen auf Informationen, Daten und Wissen. Diese stellt nur eine mögliche Sichtweise dar.
2. Von Daten zu fachlichem Wissen
Überblick über die Kapitel:
Londons Cholera Ausbruch 1854
2.1. Londons Cholera Ausbruch 1854
Wie aus Daten fachliches Wissen wird, wollen wir uns am Beispiel des Cholera-Ausbruchs 1854 im Londoner Stadtteil Soho anschauen.
Zu jener Zeit galt schlechte Luft durch Abfall und faulige Stoffe, auch Miasma genannt, als Auslöser der Cholera. Populäre Maßnahmen waren dementsprechend das Mitführen eines Blumenstraußes und das Entzünden von Schießpulverfässern zur Vertreibung schlechter Luft oder schlicht der Umzug zu Orten mit "besserer Luft".
John Snow hatte jedoch Zweifel an dieser Erklärung und den Maßnahmen. Er war der Meinung, die Ursache der Cholera sei ein Keim, den Menschen über das Wasser aufnehmen.

Noch war das ganze allerdings nur eine unbewiesene Theorie...
Wir wollen nun die Vorzüge moderner Technologien nutzen und John Snows Schritte nachvollziehen.
Dazu wollen wir uns an den Schritten des Datenlebenszyklus (Grillenberger & Romeike, 2017) orientieren und die verschiedenen Praktiken kennenlernen, die beim Umgang mit Daten eine Rolle spielen.
.
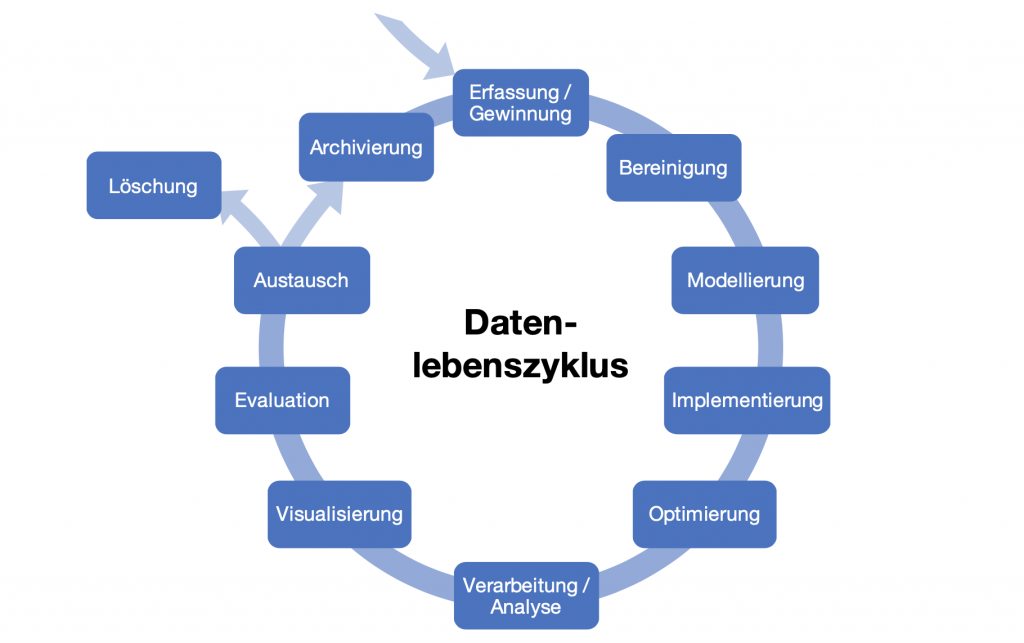
Der Datenlebenszyklus und die zugehörigen Erklärungen stellen ein Derivat der unter CC-BY-NC-SA stehenden Arbeit von Andreas Grillenberger dar.
2.2. Datenerfassung und -gewinnung

Die Datenerfassung/-gewinnung beinhaltet alle Tätigkeiten, die zu Beginn des Verarbeitungs- bzw. Analyseprozesses stattfinden und Daten für weitere Verarbeitungsschritte verfügbar machen. Dies kann die Erfassung neuer Daten, beispielsweise mit Sensoren, die Zugänglichmachung von Daten durch geeignete Strukturierung oder Konvertierung aus anderen Formaten, aber auch die Recherche nach und Abfrage von geeigneten bereits existierenden Datensätzen sein. Gegebenenfalls können Daten mehrerer Quellen bereits an dieser Stelle zusammengeführt werden.
Zu John Snows Lebzeiten wurde das Wasser in London noch von öffentlichen Wasserpumpen geholt.
Da John Snow vermutete, eine dieser Pumpen könnte verunreinigtes Wasser fördern, sammelte er nicht nur Daten zu den Cholera-Toten, sondern auch zu den Wasserpumpen.
Die Daten
Viele Daten lassen sich gut in tabellarischer Form speichern und verarbeiten. Eine Tabelle hilft Daten strukturiert aufzubewahren.
Da die Daten über unsere Pumpen andere Eigenschaften haben, als die über die Cholera Toten, verwalten wir diese in unterschiedlichen Tabellen. Der Inhalt ist exemplarisch anhand der ersten Zeilen jeder Tabelle in untenstehender Abbildung dargestellt.
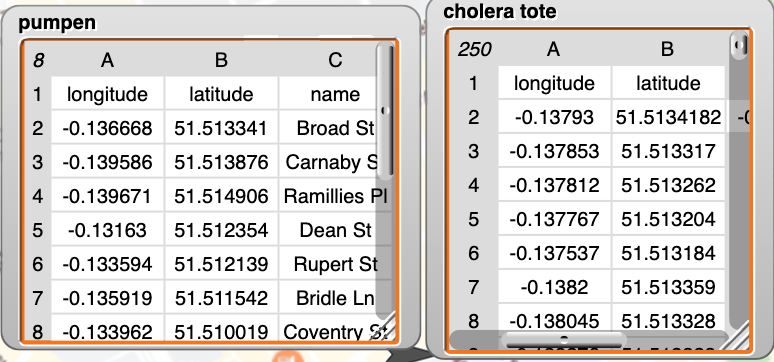
Datentypen
Zu analysierende Daten können von ganz unterschiedlicher Art sein: Mit Zahlen können wir rechnen, mit Zeichenketten nicht.
Diese unterschiedlichen Arten von Daten beschreibt man mit dem Begriff Datentyp.
Der Begriff Datentyp bezeichnet eine Menge von Objekten, die alle die gleiche Struktur haben und mit denen die gleichen Operationen durchgeführt werden können.
In unserem Beispiel finden sich bereits wichtige Datentypen:
- Längengrad (longitude): Gleitkommazahl (Float)
- Breitengrad (latitude): Gleitkommazahl (Float)
- Name des Brunnens (name): Zeichenkette (String)
2.3. Datenbereinigung

Eine Datenbereinigung wird nötig, falls die vorliegenden Datensätze ungültige (z. B. Auslesefehler von Daten eines Sensors oder Werte außerhalb des definierten/zulässigen Wertebereichs), falsche (z. B. erkennbare Messfehler) oder ungeeignet formatierte Daten (z. B. Datumsangaben als Klartext oder im falschen Format) enthalten, die gefiltert und/oder korrigiert werden müssen.
Hilfreich ist es, sich zu Beginn einen Überblick über die vorhandenen Daten zu schaffen.
Da alle Werte einer Spalte üblichwerweise vom selben Datentyp sind, könnten wir dazu beispielsweise Maximum, Minimum und den Mittelwert der Spalte ansehen. In Snap! könnte das Beispielsweise so aussehen.
Hätten wir etwa falsche Koordinaten in unserem Datensatz, die sich bspw. auf andere Londoner Stadtviertel beziehen, könnte das unser Ergebnis verfälschen.
2.4. Modellierung, Implementierung und Optimierung

Modellierung wird insbesondere zur klaren und verständlichen Strukturierung von Daten und zur Verdeutlichung von Zusammenhängen zwischen verschiedenen Datensätzen genutzt, aber auch um einen Überblick über bereits existierende Datensätze und deren Struktur zu bekommen.
Die Implementierung des Datenmodells in einem realen Datenmanagementsystem ermöglicht die Nutzung und Speicherung von Daten und ist damit grundlegend für die folgenden Praktiken.
Die Optimierung umfasst beispielsweise die Anreicherung von Daten durch weitere, beschreibende Daten zur Erreichung eines schnelleren Zugriffs (z. B. Indizierung), die Kombination von Daten, aber auch alle anderen Ansätze, die darauf abzielen, die Speicherung von und den Zugriff auf Daten möglichst effizient zu gestalten.
2.5. Verarbeitung und Analyse

Die Verarbeitung/Analyse von Daten umfasst insbesondere Aggregation von Daten, aber auch die Erzeugung neuer Informationen aus Daten unter Nutzung verschiedener Datenanalysemethoden, wie zum Beispiel Clustering, Assoziation und Klassifikation.
Beim Aggregieren von Daten geht es darum mehrere Datenpunkte zu Information zu verdichten.
Um zu erfahren, wo besonders viele Menschen an Cholera gestorben sind, lassen sich all jene Einträge in der Tabelle cholera tote mit denselben Koordinaten zählen. Jetzt enthält die Tabelle die Koordinaten nicht mehr mehrfach, sondern lediglich einmal und die entsprechende Anzahl dort verstorbener Personen.

2.6. Visualisierung

Techniken zur Visualisierung von Daten werden genutzt, um die Analyseergebnisse verständlich und gut erfassbar für den Menschen aufzubereiten.
Nun, da in der Tabelle cholera tote neben den Koordinaten auch die aggregierte Anzahl an Toten enthalten ist, können diese zusammen mit den Ortsangaben sinnvoll auf einer Karte visualisiert werden.
In Snap! hätten wir sicherlich den entsprechenden Block zur Verfügung, und auch andere Werkzeuge wie etwa Geoinformationssysteme bieten passende Optionen.

Mit der Karte konnte John Snow nun relativ leicht eine Vermutung äußern, aus welcher Pumpe kein sauberes Wasser kam.
2.7. Evaluation

Die Evaluation der Ergebnisse umfasst, neben der Beurteilung der eigentlichen Ergebnisse, auch die Einschätzung der Qualität des ursprünglichen Datensatzes und des Analyseansatzes.

Die Totenzahlen zentrieren sich also um die Pumpe an der Broad St.
Trotzdem sind einige Haushalte, in denen Menschen verstorben sind, näher an einer anderen Pumpe. Wiederum andere Haushalte liegen zwar in direkter Nachbarschaft, weisen aber keine Cholera-Toten auf.
Damit diese Datenpunkte nicht John Snows Theorie widersprechen, benötigte er entsprechende Erklärungen.
Entwickeln Sie eine mögliche Erklärung, mit der sich die Ausreißer erklären lassen!
2.8. Evaluation II (mögliche Lösung)
Mögliche Lösung zum Vergleichen:
Der große Bereich nördlich des Ausbruchs bspw. war das Gelände der Lion Brewery. Die Angestellten dort erhielten einen Haustrunk (Brauereimitarbeiter*in müsste man sein ...) oder konnten den Brunnen der Brauerei nutzen. Sie waren somit nicht auf die öffentlichen Brunnen angewiesen.
Für die Todesfälle, die weit von der kontaminierten Pumpe entfernt waren, konnte er durch zusätzliche Daten feststellen, dass hier Kinder verstarben, die auf dem Weg zur Schule kontaminiertes Wasser an der Pumpe tranken.
2.9. Austausch, Archivierung und Löschung

Der Austausch von Daten kann die Analyseergebnisse aber auch die Originaldaten umfassen und auf verschiedenen Wegen stattfinden.
Die längerfristige Archivierung von Daten wird genutzt, um diese für zukünftige (oft noch nicht vorhersehbare) Zwecke zu nutzen. Durch die Archivierung wird die weitere Nutzung von Daten für eine gewisse Zeit unterbrochen, sie werden aber für mögliche spätere Nutzungen weiterhin vorgehalten.
Die Löschung der Daten kann aus verschiedenen Gründen erfolgen: Neben der Löschung zur Gewinnung von Speicherplatz, kann sie beispielsweise auch nötig sein, um das Persönlichkeitsrecht von Personen zu wahren. Durch die (sichere) Löschung wird, im Gegensatz zur Archivierung, eine spätere Verwendung der Daten unterbunden.
Mit dem Austausch seiner Analyseergebnisse mit den entsprechenden Stellen konnte John Snow die Stilllegung der "Broad St."-Pumpe erreichen. Nun hätte er seine Daten natürlich löschen können und damit den Datenlebenszyklus beenden. Er entschied sich aber seine Daten noch für ein weiteres Experiment zu verwenden – sein "großes Experiment".
Weiterführende Hinweise:
Mitte des 19. Jahrhunderts hatte der Londoner Stadtteil Soho aufgrund des großen Zustroms von Menschen und des Mangels an sanitären Einrichtungen ein ernsthaftes Problem mit Schmutz. Hinzu kam, dass Soho bisher nicht an das Londoner Kanalisationssystem angeschlossen war.
Weiterhin war auch der Unrat von Kuhställen oder Schlachthäusern Teil des allgemeinen Schmutzproblems. Die Senkgruben – zu jener Zeit hoffnungslos überfüllt – konnten die Abfälle nicht mehr aufnehmen. Daher wurden die Abfälle auch in die Themse entsorgt und trugen damit auch noch zur Verunreinigung der Wasserversorgung bei.
John Snows Originalkarte ist sowohl eines der frühesten als auch eindrucksvollsten Beispiele wie Datenvisualisierungen genutzt werden können:

John Snows Originalkarte zeigt die Cholera Toten durch gestapelte Rechtecke. Die kontaminierte Pumpe befindet sich an der Kreuzung zwischen Broad St und Cambridge St (heute Lexington St).
2.10. Snows großes Experiment
Aufgrund der Karte hatte John Snow nun starke Indizien, dass kontaminiertes Wasser die Ursache der Cholera-Epidemie war. Ermutigt von seinen Erkenntnissen des Broad Street Cholera-Ausbruchs, wandte er sich einem anderen Stadtteil Londons zu. Dort waren die beiden Firmen Southwark & Vauxhall und Lambeth Company für die Wasserversorgung zuständig.
- Die Lambeth Company (in der Karte rot) bezog ihr Wasser flussaufwärts aus einem sauberen Abschnitt der Themse.
- Southwark & Vauxhall hingegen bezogen ihr Wasser aus der Gegend um Battersea Park. Da dort viele Abfälle in den Fluss geleitet wurden, war dieses Wasser jedoch verunreinigt.
Die Gegend, in der beide Firmen einen Teil der Wasserversorgung übernommen hatten, bot optimale Bedingungen für Snows "Grand Experiment": Mit Ausnahme der Wasserversorgung konnten beide Gruppen als identisch angesehen werden.

John Snows Karte für sein Grand Experiment
In seinen Notizen stellt er dazu fest:
“Each company supplies both rich and poor, both large houses and small; there is no difference either in the condition or occupation of the persons receiving the water of the different Companies … there is no difference whatever in the houses or the people receiving the supply of the two Water Companies, or in any of the physical conditions with which they are surrounded …”
Diesmal sammelte er neben der Anzahl der Cholera-Toten auch den Namen des jeweiligen Wasserversorgers. Dann summierte er diese und trug sie aufgeschlüsselt nach Wasserfirma in eine Tabelle ein.
Stadtteil | Häuser | Tote |
S&V | 40046 | 1263 |
Lambeth | 26107 | 98 |
Rest of London | 256423 | 1422 |
Snows Experiment auswerten
Um die Verwaltung zu überzeugen, reichten die absoluten Zahlen noch nicht, da die beiden Firmen unterschiedlich viele Haushalte mit Wasser versorgten. Aus diesem Grund musste er die beiden Größen nun noch ins Verhältnis setzen.
Stadtteil | Häuser | Tote | Tote pro 10.000 Häuser |
S&V | 40046 | 1263 | 315 |
Lambeth | 26107 | 98 | 38 |
Rest of London | 256423 | 1422 | 55 |
Schlussfolgerungen
Mit seinen Untersuchungen konnte John Snow beweisen, dass tatsächlich kontaminiertes Wasser und nicht schlechte Luft (Miasma) schuld am Ausbruch der Cholera war. Indem er den Hebel der Pumpe an der Broad Street entfernte, konnte er die Epidemie stoppen.
Mittlerweile wissen wir, dass John Snow mit der Methodik in seinem großen Experiment durchaus einige Probleme hatte (vgl. Koch & Denike, 2006). Trotzdem: Seine Erkenntnisse waren richtig und die Einbeziehung von Daten hob ihn von vielen Zeitgenossen ab.
Und wie sagt man doch gleich? "Traue keiner Statistik, die du nicht selbst gefälscht hast." 😉
John Snows Veröffentlichung
Seine Erkenntnisse hielt Snow auch schriftlich fest. Die Veröffentlichung von damals kann heute beispielsweise digital bei Google Books abgerufen werden.
3. Big Data
Überblick über die Kapitel:
Big Data
Metadaten
Bias
3.1. Big Data
Muster in riesigen Datenmengen zu finden, kann unglaublich wertvoll sein – für die Gewinnung wissenschaftlicher Erkenntnisse genauso wie für die Festsetzung von Preisen, das Generieren von Kaufempfehlungen oder die Aufdeckung verdächtiger Aktivitäten.
Nicht umsonst setzen viele Unternehmen und Wirtschaftszweige auf "Big Data". Was aber bedeutet "Big Data"? Wie groß müssen Daten sein, um als "Big Data" bezeichnet werden zu dürfen?
Eine klare Grenze kann man hier nicht ziehen. Um aber eine Vorstellung davon zu vermitteln, wie groß Daten für "Big Data" nun sein müssen, wird meist das 3V-Modell von Gartner (das sind die mit dem Hypecycle) herangezogen. Im 3V-Modell bezieht sich die Größe (das "Big") auf drei Dimensionen.

- Volume (Ansteigendes Volumen)
Volumen bezieht sich auf die stetig steigende Menge an Daten.
In Modul 00 haben wir uns bereits angesehen, wie unglaublich viele Daten in nur wenigen Sekunden in sozialen Netzwerken generiert werden: Jeder Videoupload oder jeder Tweet, aber auch jeder Klick und jeder Einkauf erzeugt Daten. Was dabei für Datenberge entstehen, zeigt diese Grafik. In nur 30 Sekunden entstehen beispielsweise über 500.000 Gigabyte an Daten.
- Variety (zunehmende Vielfalt)
Die zunehmende Vielfalt bezieht sich auf die vielen verschiedenen Arten von Daten (Bilder, E-Mails, Tonaufnahmen, Banktransaktionen, Tracking-Daten), die erzeugt, gespeichert und verarbeitet werden.
Diese Vielfalt ist eine der großen Herausforderungen bei "Big Data". Neben sogenannten strukturierten Daten, die wir vorhin bereits verwendet haben, werden immer öfter auch unstrukturiert oder teilstrukturiert vorliegende Daten verwendet.
- Könnten Daten auch strukturiert in Tabellen abgelegt werden, sprechen wir von strukturierten Daten. Beispiele für strukturierte Daten sind die Daten von John Snow, die wir im letzten Kapitel verwendet haben, oder die Kundenstammdaten eines Online-Shops. Solche Daten haben den Vorteil, dass Verwaltung und Zugriff effizient möglich sind (Wir wollen alle Vornamen unserer Kunden? Kein Problem!).
- Mit dem Begriff unstrukturierte Daten bezeichnen wir digitalisierte Informationen, die eben nicht in einer solchen formalisierten Struktur vorliegen. Das können Bilder, digitale Texte, Tonaufnahmen, aber auch die kontinuierlich anfallenden Daten eines Sensors sein.
- Teilstrukturierte Daten (auch: semistrukturierte Daten) stellen eine Mischform aus strukturierten und unstrukturierten Daten dar. In einer E-Mail beispielsweise finden sich einige strukturierte Daten (Absender, Adressat, Uhrzeit, Betreff). Der Rumpf der Nachricht besteht aus beliebigem Text, Bildern oder sonstigen Dateianhängen und ist damit unstrukturiert.
Der Anteil unstrukturierter Daten an der Gesamtdatenmenge liegt laut IBM übrigens bei circa 80%.
- Velocity (ansteigende Geschwindigkeit)
Die zunehmende Geschwindigkeit hat zwei Dimensionen. Zum einen nimmt die Geschwindigkeit, mit der die Daten erzeugt werden, stetig zu (siehe auch Volumen). Zum anderen nimmt dadurch auch die notwendige Verarbeitungsgeschwindigkeit zu.
Oft muss diese Verarbeitung sogar in Echtzeit (also nahezu simultan mit den realen Ereignissen oder zumindest mit möglichlist geringer Verzögerung) erfolgen, was bei der schieren Menge an erzeugten Daten keine leichte Aufgabe ist. Wenn Sie beim Onlineshopping mit Ihrer Kredtikarte bezahlen, wird nicht nur geprüft, ob die eingegebene Kreditkartennummer bei Ihrer Bank registriert ist. Es wird auch geprüft, ob Sie Ihr Kreditkartenlimit einhalten, ob die Zahlung verdächtig aussieht, usw. Erst, wenn alle Prüfungen erfolgreich sind, wird eine Zahlung an den Händler angestoßen. Und das alles darf natürlich nur wenige Sekunden in Anspruch nehmen. Ähnlich sollte ein Frühwarnsystem für Erdbeben bereits bei ersten Signalen Warnungen geben können und nicht erst einige Stunden auf die Auswertung der Daten warten müssen.
3.2. Metadaten
Datensätze enthalten nicht nur die eigentlichen Daten, sondern auch Daten über sich selbst. Beispielsweise enthalten Fotos Daten über den Aufnahmeort, das Aufnahmedatum, die getätigten Einstellungen oder den Fotographen.
Bei diesen Informationen über die Daten selbst spricht man von Metadaten.
Metadaten können bei der Arbeit mit Daten sehr nützlich sein. Ohne Metadaten könnten wir Dateien auf unserem Computer nur schwer durchsuchen oder filtern. Auch das Organisieren unserer Musikbibliothek wäre deutlich aufwändiger, wenn Informationen über den Songtitel, den Interpreten, das Album oder das Genre fehlen würden. Und auch wenn wir Daten analysieren wollen, liefern uns Metadaten zusätzliche Informationen.
Da Programme Metadaten oft nicht anzeigen, kann es leicht passieren, dass unsere Privatsphäre ohne unser Wissen verletzt wird, wenn Daten online gestellt werden, wie die folgenden Beispiele aus dem Buch "Blown to Bits" von Hal Abelson, Ken Ledeen und Harry Lewis zeigen.
Metadaten von Fotos erlauben es die Kamera zu identifizieren
Harry Potter and the Deathly Hallows is, as far as anyone knows, the last book in the Harry Potter series. Its arrival was eagerly awaited, with lines of anxious Harry fans stretching around the block at bookstores everywhere. One fan got a prerelease copy, painstakingly photographed every page, and posted the entire book online before the official release. A labor of love, no doubt, but a blatant copyright violation as well. He doubtless figured he was just posting the pixels, which could not be traced back to him. If that was his presumption, he was wrong. His digital fingerprints were all over the images.
Digital cameras encode metadata along with the image. This data, known as the Exchangeable Image File Format (EXIF), includes camera settings (shutter speed, aperture, compression, make, model, orientation), date and time, and, in the case of our Harry Potter fan, the make, model, and serial number of his camera (a Canon Rebel 350D, serial number 560151117). If he registered his camera, bought it with a credit card, or sent it in for service, his identity could be known as well. (Abelson et al., 2008; S. 24.)
Metadaten eines Worddokuments in Form von Textänderungen verraten Geheimnisse
In October, 2005, UN prosecutor Detlev Mehlis released to the media a report on the assassination of former Lebanese Prime Minister Rafik Hariri. Syria had been suspected of engineering the killing, but Syrian President Bashar al-Assad denied any involvement. The report was not final, Mehlis said, but there was “evidence of both Lebanese and Syrian involvement.” Deleted, and yet uncovered by the reporters who were given the document, was an incendiary claim: that Assad’s brother Maher, commander of the Republican Guard, was personally involved in the assassination.
Microsoft Word offers a “Track Changes” option. If enabled, every change made to the document is logged as part of the document itself—but ordinarily not shown. The document bears its entire creation history: who made each change, when, and what it was. Those editing the document can also add comments—which would not appear in the final document, but may help editors explain their thinking to their colleagues as the document moves around electronically within an office. (Abelson, 2008; S.77)
Überprüfen Sie Ihr Verständnis mit den folgende Fragen zu Daten bzw. Metadaten.
"Metadata" by Beauty and Joy of Computing by University of California, Berkeley and Education Development Center, Inc., used under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License / Desaturated from original
3.3. Bias
Die Art und Weise, wie Daten für eine Analyse erfasst werden, hat großen Einfluss auf das Ergebnis der Analyse.
Data Bias
Wenn wir basierend auf den Sensordaten eines intelligenten Kühlschranks untersuchen möchten, wie oft Menschen ihren Kühlschrank öffnen, wen haben Sie dann ausgeschlossen? Wer könnte überrepräsentiert sein? Ein intelligenter Kühlschrank ist (zumindest aktuell) ein Luxusartikel. Deshalb werden vor allem reiche Menschen zu unserer Studie beitragen. Ist diese Gruppe repräsentativ für alle?
Dies ist nur ein dummes Beispiel, aber denken Sie darüber nach, was passiert, wenn wir "Big Data" zur Analyse der Wirksamkeit eines Medikaments einsetzen und unsere Daten nur Männer umfassen. Sollten wir unsere Erkenntnisse dann automatisch auf Frauen übertragen?
Natürlich nicht! Es gibt physiologische Unterschiede zwischen Männern und Frauen. Sie zu einer Gruppe zu verallgemeinern ist schlichtweg falsch. Das ist übrigens ein reales Problem: Bei der Analyse von Gesundheitsdaten wurden in der Vergangenheit häufig Personengruppen benachteiligt, die in den Datenstichproben unterrepräsentiert waren.
Von einem Data Bias (Datenbias) sprechen wir, wenn Daten Verzerrungen aufweisen, nicht repräsentativ sind oder unbewusste Vorurteile widerspiegeln.
Es ist dementsprechend enorm wichtig, aber auch eine große Herausforderung, dass die erfassten Daten auch die Gruppe von Menschen, die untersucht werden soll, genau wiedergibt. Daher sollte man sich über mögliche Verzerrungen in den Daten stets bewusst sein und entsprechende Maßnahmen treffen, diese Verzerrungen zu reduzieren.
Um einen Eindruck davon zu bekommen, welche Auswirkungen die Perspektive auf die Erhebung von Daten hat, spielen Sie das folgende Spiel!
Algorithmic Bias
Daten können einen ungewollten Bias - Vorurteile, Verzerrungen oder Neigungen - enthalten. Gerade, wenn diese Daten in algorithmischen Entscheidungen (wir erinnern an Modul 05) involviert sind, sollte man deshalb besondere Vorsicht walten lassen. Verzerrungen in Daten führten dazu, dass
- ein Algorithmus Menschen mit dunkler Hautfarbe als Gorillas identifizierte
- oder ein intelligentes System zur Auswahl von Bewerbern, Bewerber aussortierte, von denen es annahm, es handle sich um Frauen. Dies war sogar dann der Fall, wenn die Bewerbung gar kein Geschlecht erwähnte, sich dieses Merkmal aber aus anderen Informationen (etwa der Mitgliedschaft in einem Frauenverein) erschließen ließ.
Unter dem Stichwort Algorithmic Bias werden verschiedene damit verbundene Probleme bzw. Lösungen diskutiert und teilweise auch schon umgesetzt.
Der Abschnitt Bias stellt ein Derivat des unter CC-BY-SA stehenden CS Field Guide Kapitels dar.
4. Daten im Unterricht
Überblick über die Kapitel
Analysewerkzeuge für den Unterricht
Daten- und Datenanalyse im Unterricht
4.1. Analysewerkzeuge für den Unterricht
Herzlichen Glückwunsch! Sie haben Datenanalysen verwendet, um die Ursache einer Epidemie zu identifizieren und haben damit nun (hoffentlich) einen Eindruck davon gewonnen, wie mit Computern große Datenmengen beherrscht werden können. John Snow wäre von einem solchen Werkzeug begeistert gewesen.
In einer digitalisierten Welt sind Daten und der Umgang mit selbigen ein wichtiges Thema. Die Analyse und Visualisierungen großer Datenmengen führen zu interessanten Fragestellungen: Welche Ursachen hat der Einbruch der Lebenserwartung im Jahre 1918? Wie verbreitet sich ein Grippevirus? Wie häufig treten bestimmte Zeichenfolgen in der Literatur auf?
Snap!
Sie haben nun ja bereits ein Beispiel gesehen, wie Sie Daten mit Snap! auswerten können. Weitere Ideen gibt es unter anderem in der Snap! Cloud.
Tabellenkalkulation
Ein beliebtes Werkzeug, um Daten auszuwerten oder zu visualisieren sind natürlich Tabellenkalkulationsprogramme. Hier finden Sie ein Beispiel, wie mithilfe einer Tabellenkalkulation ein Klimadiagramm erstellt werden kann. Im Mathematikunterricht können auch Häufigkeiten in Zufallsdaten ermittelt werden, um beispielsweise das Gesetz der großen Zahlen nachzuvollziehen.

Orange 3
Orange 3 erlaubt die Datenauswertungen und -visualisierungen durch das Platzieren und Verbinden von Widgets (wie der Darstellung einer Tabelle (Data Table) oder einem Box Plot) auf einer Leinwand. Um Orange 3 verwenden zu können, müssen Sie das Programm allerdings installieren.
Wie damit COVID-19 Daten exploriert werden können, zeigt beispielsweise dieser Blog-Eintrag.

Screenshot von Orange 3 (Software lizenziert unter GNU GPL-3.0)
BLIF
Der Blick von oben (BLIF) ist ein Werkzeug, mit dem Satellitenbilder ausgewertet werden können. Innerhalb des Werkzeugs stehen nicht nur jede Menge Satellitenbilder, sondern auch jede Ideen zur Verfügung. Anhand der Satellitenbilder kann dann beispielweise die Landnutzung untersucht werden.

Google Ngram Viewer
Googles Ngram Viewer untersucht, wie häufig in Büchern ausgesuchte Wortfolgen, sogenannte n-grams, benutzt werden. Innerhalb des Werkzeugs können beliebige Wortfolgen analysiert und miteinander verglichen werden. Im Beipiel unten sehen Sie eine Gegenüberstellung der Ngramme "Er" und "Sie". Tolle Ideen für den Ngram Viewer im Geschichtsunterricht gibt's hier.

Messwerte erfassen und auswerten
Daten "analog" auswerten
Die Analyse von Daten muss selbstverständlich nicht mit dem Computer erfolgen. Wie wäre es, alle Schulwege der Schülerinnen und Schüler auf einer Karte einzeichnen zu lassen und dann die Zusammenfassung aller Wege zu analysieren. Wo sollten Schülerlots*innen stehen, wo reichen Zebrastreifen aus? Auch andere Daten, etwa die Ergebnisse der eigenen Umfrage können natürlich ohne PC analysiert werden.4.2. Daten- und Datenanalyse im Unterricht
Wie könnten (welche) Daten bzw. Datenanalysen in Ihrem Fach über die gerade gesehenen Beispiele hinaus eingesetzt werden?
5. Selbsttest
6. Literaturempfehlungen
Infos zum Video:
In seinem Vortrag "The best stats you've ever seen" zeigt Hans Rosling Daten wirklich, wie wir sie noch nie gesehen haben. Der Vortrag ist es wirklich wert ihn anzuschauen. Er weiß mit seinem 20 minütigen Vortrag nicht nur zu begeistern, sondern liefert auch spannende Einblicke in die Entwicklung unserer Welt.

Infos zum Buch:
Egal wohin wir gehen, was wir bestellen, photographieren oder wo wir Geldabhebungen machen, wir erzeugen unglaublich viele Daten. Das Buch enthält viele Beispiele wie Computer diese Daten verwenden. Blown to Bits hinterfragt die Welt, die wir damit erschaffen und gibt das Wissen, das wir brauchen, um unsere eigene digitale Zukunft mitzugestalten, ohne dass andere es für uns tun. Es lässt uns paradoxe Wahrheiten über digitale Daten entdecken und erfahren, wie so jahrhunderte alte Annahmen über Privatsphäre, Identität und persönliche Kontrolle auf den Kopf gestellt werden.
Verwendete Literatur im Überblick
- https://www.datamation.com/big-data/structured-vs-unstructured-data.html
- https://www.the-scientist.com/foundations/john-snows-grand-experiment-1855-43152
- http://oceantracks.org/sites/oceansofdata.org/files/Module5_FINAL.pdf
- https://scheinkorrelation.jimdo.com/
- Hao, K. & Stray, J. (2019), Can you make AI fairer than a judge?, online abrufbar unter:
https://www.technologyreview.com/2019/10/17/75285/ai-fairer-than-judge-criminal-risk-assessment-algorithm/ - Abelson et al. (2008): Blown to Bits: Your Life, Liberty, and Happiness After the Digital Explosion, Adison-Wesley, 2008.
- Finzer, W., Busey, A., & Kochevar, R. (2018): Data-Driven Inquiry in the PBL Classroom. Science Teacher, 86(1), 28-34.
- Grillenberger, A. & Romeike, R. (2015): Analyzing the Twitter Data Stream using the Snap! Learning Environment, In Informatics in Schools. Curricula, Competences, and Competitions - 8th International Conference on Informatics in Schools: Situation, Evolution, and Perspectives, ISSEP 2015, Ljubljana, Slovenia, September 28 - October 1, 2015, Proceedings (Brodnik, Andrej, Vahrenhold, Jan, eds.), Springer, Cham, volume 9378, 2015.
- Jannidis, F. et al. (2017), Digital Humanities, S. 206.
- Koch, T. & Denike, K. (2006): Rethinking John Snow's South London study: A Bayesian evaluation and recalculation
- Rosling, H. (2009). Gapminder. GapMinder Foundation http://www.gapminder.org, 91.
- Siegel, M., Deuschle, J., Lenze, B., Petrovic, M., & Starker, S. (2016): Automatische Erkennung von politischen Trends mit Twitter – brauchen wir Meinungsumfragen noch? DGI-Praxistage 2016.
7. Abschluss Modul 08
Super, Sie haben MODUL 08 erfolgreich beendet!
